
Industries of all kinds are being shaken up by contemporary big data technologies, and the mining industry is one of them. Increasingly, leading companies are actively seeking new value opportunities and embracing new operational practices centered around machine learning and big data. Such initiatives to date include integrating predictive analytics into day-to-day operator workflows, investing in comprehensive Internet-of-Things (IOT) control systems at a site and building out multi-stakeholder, enterprise-wide cloud ecosystems. Over the coming months, members of IMEC’s innovation team hope to dig further into each of these general topics to shed more light onto the future role of big data in mining. We begin, however, by taking a novel view on a subject very close to our core business, the maintenance of site dewatering pumps.
Preventative maintenance, as applied to dewatering pump replacement scheduling, has been a part of standard mining operations for a long time. Using schedules that are often regulatory in nature, and other times based on ad-hoc, relatively cautious rules-of-thumb, regular pump maintenance ensures that critical components are replaced prior to failure. However a commonly adopted strategy in the industry today is to enforce rigid preventative maintenance schedules that call for the removal and scrapping of perfectly good components prior to the end of their natural wear life. Mine operators often view the cost of this wastage through under-utilization of the components as negligible, on the grounds that a catastrophic failure would have much greater significance on site profitability than the cost of replacement parts.
But what if there was a way that a mine operator could safely assess the health of a primary dewatering pump unit in real time, and instead of changing out components on a rigid schedule, change the components only when an indication of serviceable life expiry presented? IMEC General Manager, Martyn Abbott, thinks this is a possibility worth considering.
“While predictive schedules could in some sense be more disruptive than planned shutdowns due to shorter time for response, pump maintenance crews and critical spares are typically available around the clock at underground sites. Hence the short notice periods may not have significant impact to the repair period (if any at all).”
Martyn cites examples of this seen in the PETRA Data Science FORESTALL algorithm developed for the Newcrest Unearthed challenge.
What kind of data would feed into such a predictive analytic system and how would such a system work? Real-time data taken from the dewatering system instrumentation (flow meters, pressure sensors, vibration sensors, limit switches, etc.) could easily be routed to centralised logging systems, which themselves would connect to appropriate computing platforms for running analytics using specifically designed algorithms. Alongside the larger well known tech industry players (think IBM, GE etc.) that are pioneering new ways of working with big data sensor streams, there are many smaller disruptors doing the same such as Alluvium.
According to former Fellow of New York’s Insight Data Science program, Dr Stuart Jackson, the real challenge lies in building the right form of predictive model for a given problem.
“Truly successful predictive models typically only arise when deep domain expertise is joined with the appropriate data pre-processing and algorithmic approaches”.
In data pre-processing, the goal is to achieve the cleanest and richest representation of the input data sources prior to model building. Sometimes this might involve a simple preparation step (e.g., getting all data streams into common formats, or taking into account known trends in the dataset domain based on existing knowledge, known as “de-trending time-series”). In the extreme, more layered and hierarchical representations of features (i.e., complex combinations of raw inputs) might be created, so called “deep learning representations”.
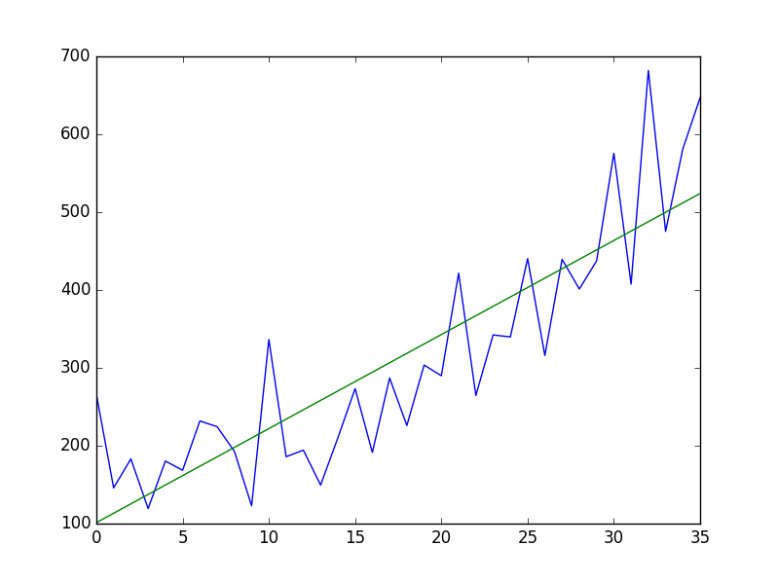
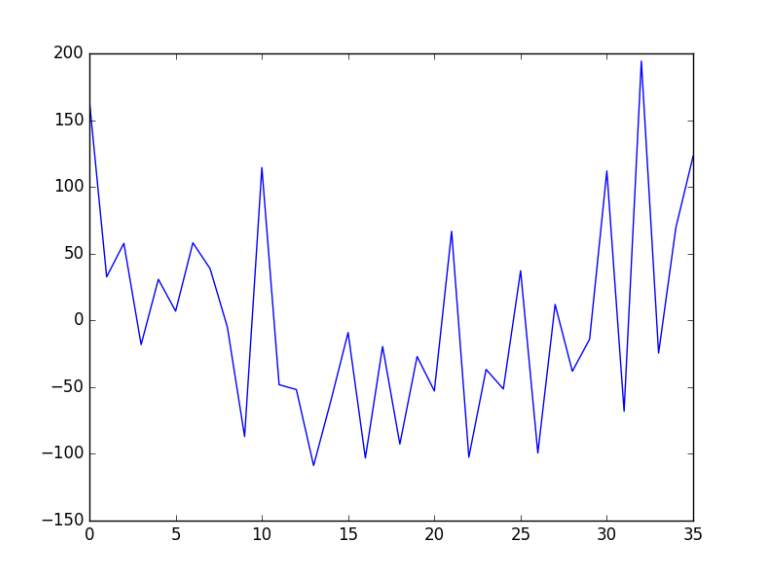
Example of Detrending Time-Series on a dataset to improve a modelling algorithm. Reference: https://machinelearningmastery.com/time-series-trends-in-python/
As for the algorithms that govern the analysis of big datasets, various techniques are probably worthwhile exploring at the prototype stage. For example, when working with historical sensor data one might use standard time-series forecasting methods (e.g., ARIMA models) adapted appropriately for the domain. This could be particularly helpful in determining the key data features related to a particular event that might be of interest (i.e., component wear). However, building out a real-time prediction system would likely require a more nuanced understanding of interactions between the equipment and maintenance personnel, with deeper representational (e.g., LSTM) and modeling techniques (e.g., reinforcement learning) possibly having a role to play. But all of these efforts should be tempered by domain expertise and regulatory safety requirements, as noted by Dr Jackson:
“It’s up to the building inspector, not the house builder, to decide whether a house’s foundations meet regulatory and safety requirements”.
Increasing the utilization and service life of components required for dewatering pump maintenance would of course have a direct effect on suppliers to this industry. A decrease in sales due to greater utilisation and service life, will encourage smaller suppliers to innovate through diversification and product lines improvements to remain competitive. Innovations such as deep learning, have a tendency to lead to further disruption within a given industry, as new challenges are uncovered in an ever-changing landscape.
It is clear that the increasing trend in identifying and implementing new applications for machine learning, coupled with the ongoing focus on improving mine efficiency, is fertile grounds for sowing the seeds of innovation within the field of mine maintenance. It is quite possible that as the mining industry gains further exposure to the potential upside of developing bespoke deep learning systems in mine maintenance, we may see a future where capital investment decisions are based on computer models as the primary influencing factor, as well as regulatory bodies and suppliers adapting to service an industry where algorithm driven decision making is the norm.